Technical FAQ |
  
|
Technical FAQ |
|
|
Question: Will EurekaLog work, if I compile project from command line? We have a build script on our build server. Answer: Yes. It is possibly to use EurekaLog with command-line compilation. Please refer to our documentation for more information.
Question: Do I need to distribute any additional files for application compiled with EurekaLog? Answer: No. EurekaLog-enabled applications are self-contained. All code and data are injected into executable module, so you do not need any additional files. No DLLs, no .map files, no .tds files.
Question: Do I need to deploy OpenSSL's DLLs when using SSL/TLS? Answer: No. EurekaLog uses WinHTTP API for HTTPS and Security Support Provider Interface (SSPI) for RAW SSL/TLS.
Question: How much does EurekaLog increase compiled file size? Answer: About 1 Mb of EurekaLog's code (worst case, usually increase is smaller, depends on project settings) plus 5-18% file size of debug information (depends on project settings).
Here is a sample data: a 40 Mb executable has about 22 Mb .map file. This .map file is processed by EurekaLog to produce a total of 7 Mb (uncompressed) debug information, which consists of:
This debug information can be compressed into 3.5 Mb, therefore difference between uncompressed and compressed debug information is 4.5 Mb, meaning:
This debug information can also be stripped from all names, or keeping unit names only (see debug info settings), debug info for RTL / VCL can be reduced - thus making increase even smaller.
There is also code for EurekaLog, which is typically about 1 Mb (exact size may vary depending on your IDE, bitness of your project, and how many standard units it already contain).
Note: we do not recommend to compress debug information. Compressing debug information means that your executable will start up slower, because it needs to unpack and prepare debug information. Storing debug information unpacked means that it is ready to use, no startup delays. In other words: it is a typical "trade memory for speed". That is why compressing debug information is disabled by default.
See our guide on project settings.
Question: Can EurekaLog decrease an application's performance? Answer: That depends on your application, but usually - no. That's because EurekaLog is not active in your application at all - until exception will be raised. When exception is raised - EurekaLog collects information. So, if your application raises a lot of exceptions - then yes, EurekaLog can slightly slow down its execution. Note that over-using of exceptions is a bad practice in general. You can solve this by disabling EurekaLog for particular exceptions or for particular code blocks.
There are also memory problems tracing features in EurekaLog. You can disable them for best performance (it will be unaffected). If you enable such features - EurekaLog will collect information about memory blocks in your application. This can slow down your application. Exact estimates depends on your application (how often it allocates/releases memory). Typical slow down is about 5%. This can be worse in certain applications - for example, if you constantly allocate huge amount of small memory blocks.
If you are experiencing performance issues in your application - see this article for troubleshooting.
Question: Does EurekaLog support TObject exceptions? Answer: No. While the low-level RTL code can work with any exceptions including child classes from TObject:
type
However, the Exception class from the SysUtils unit contains official exception hook points (GetExceptionStackInfoProc, GetStackInfoStringProc, CleanUpStackInfoProc), which are not present in TObject nor other classes. So, the above code example will not work correctly with EurekaLog. The fixed code should look like this:
type
Additionally, the VCL/CLX/FMX or any other high-level framework expects exception to be a child class from the Exception class and not something else. For example:
type
Question: I do not want to expose my internal code information (routine names, etc.) Answer: No problem! You can protect your information with password, you can exclude certain code blocks from inclusion (by using {$D-}/{$D+} compiler directives), you can include only unit names and line numbers (but not class and routine names), or you can even offload all names to external file.
Question: Why can't I see "Send" button (and e-mail input field) in exception dialog, even though I set up sending in options? Answer: This is probably the "Do not save duplicate errors" option working. When exception occurs for the first time - it will be written to log and sent to developer (there will be "Send"/"Don't send" buttons). If the same exception will occur for the second time:
"Same exception" relation is established via BugID property.
Question: Why do I see different errors in dialog and bug report? Answer: This happens when you have more than one exception to handle. It is usually due to second exception being raised inside exception handler code for the first exception. For example:
try // Low-level error (a.k.a. original, first, bottom, inner, nested, root) raise ERangeError.Create('Invalid item index'); except // High-level error (a.k.a. introduced, last, top, outer, chained) Exception.RaiseOuterException(EFileLoadError.CreateFmt('Error loading file %s', [FileName])); end;
or:
Obj := TSomeObject.Create; try // Low-level error (a.k.a. original, first, bottom, inner, nested, root) raise ERangeError.Create('Invalid item index'); finally // Secondary error (a.k.a. introduced, last, top, outer, chained) FreeAndNil(Obj); // <- some exception here end;
Such exceptions are called "chained/nested exceptions". The idea here is that you are interested in original (first) exception as source for the issue - that is why this exception will be included in bug report. However, the last exception may represent more accurate message for the user - that is why this exception is shown in dialogs. You can control this behavior in EurekaLog's options.
See also: Nested/Chained Exceptions.
Question: Why does EurekaLog show call stack items in different colors? What do these colors mean? Answer: EurekaLog paints call stack with different colors to help you understand how call stack was build. See this article for a detailed explanation.
Question: Why does call stack not match the source code? Answer: This happens in Win32, because x86-32 does not have a reliable way to obtain a call stack. This does not happen in Win64 (usually), because x86-64 uses special constructs to store call stack, so it is possible to obtain 100% reliable call stack.
Call stack on Win32 is build either by using frames or using heuristic. Both methods will generate different results, but there is no guarantee that call stack will match the source code exactly. You must expect false-positive and missing entries in the call stack. You can learn more about differences in build methods in this article.
EurekaLog can help you to understand how call stack was build by using different colors.
Question: Why does exception not match the call stack? Answer: This happens when execution flow goes via invalid path. For example, you can have code that calls function via procedural variable, or code that calls virtual method. Such code calls sub-routine via a pointer. If that pointer is not initialized or corrupted - some random code will be called, which usually is totally unrelated to the caller code. Few simple examples are below:
var
Such bug can manifest itself in 5 possible ways:
Additionally, if you see that message for access violation exception contains addresses, which are exactly match or are very close to one of the following:
then you are probably have either this issue (calling code via invalid pointer; typically: calling methods of already deleted object or interface) or issue of using already deleted memory (such as using fields of deleted objects).
See also: EAccessViolation.
Question: Why do call stacks for background threads not match exception thread? Answer: This happens because it is not possible to capture stacks of all threads in application atomically. While external process (such as debugger) can suspend the whole process (and then retrieve call stacks for threads which are frozen at the same moment) - this is not possible for EurekaLog, which operates within the process. We are forced to get call stacks for threads in a cycle, suspending each thread individually. Naturally, threads are continue to run while EurekaLog runs thread suspend cycle. That is why you may see that some threads will be slightly ahead of normal execution paths.
Question: Why does Viewer shows "Success" when opening the report, but no new report appears? Answer: This can happen if you are opening the same report twice. Alternatively, it could happen if you have two report about the same problem (in other words, same BugID) and Viewer is in DataBase mode:
View mode In this mode EurekaLog Viewer works like pure viewer with no database functionality. All reports from bug report file will be displayed - regardless of BugID property. I.e. no merging will occur, no "Count" field will be increased. Report list will be hidden if bug report file contain only single bug report.
View mode
Note: View mode is indicated by "[View mode]" postfix at title and flat coloring of the toolbar.
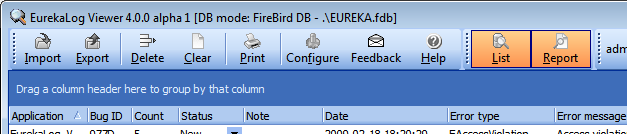
Database mode In this mode EurekaLog Viewer adds every opened report to one global database. I.e. all once opened reports are stored in single place. You can manage them, delete, change, etc. All imported bug reports will be merged by BugID. Only first report with each particular BugID is stored in the database, all following reports with the same BugID will increase "Count" field of first report and will be discarded. If no database is configured, in-memory database will be used. Imported reports are not deleted from disk after import.
DB mode
Note: DB mode is indicated by "[DB mode: XXX]" postfix and gradient coloring of the toolbar. The "XXX" part displays additional information about current database: its type (it is 'FireBird DB' in this example) and location (it is local file '.\eureka.fdb' in this example).
When your Viewer is in DB mode - it will act like a bug tracker, e.g. reports with same BugID are considered to be about the same problem, so these reports will be merged by increasing the Count column. This allows you to sort your problems by occurrences and fix the "hot" one first.
Question: My question is not listed in this FAQ? Answer: Take a look at our video tutorials, another FAQ sections, "How to" section, or contact our support.
| ||||||||||||||||||||||||||||||||||||||||||||||||